It's not about the tree...

|
This is a blog about the Cedar Policy Language. I'm Darin McAdams, Sr. Principal Engineer in Amazon Web Services and part of the team that originally built Cedar. This is my personal blog covering Cedar topics such as the language design, usage patterns, and various other curiosities. All opinions are my own. All intelligent statements probably come from my teammates. |
Recent Posts
- December 5, 2023 - A quick guide to partial evaluation
- July 16, 2023 - How well do Cedar policies compress?
- June 27, 2023 - Why doesn't Cedar allow wildcards in Entity Ids?
- June 25, 2023 - Why doesn't Cedar have regexes or string formatting operators?
- June 25, 2023 - Why doesn't Cedar support floating-point numbers?
- June 25, 2023 - Why does Cedar ignore policies that error?
- June 25, 2023 - Why do Cedar policies end with a semi-colon?
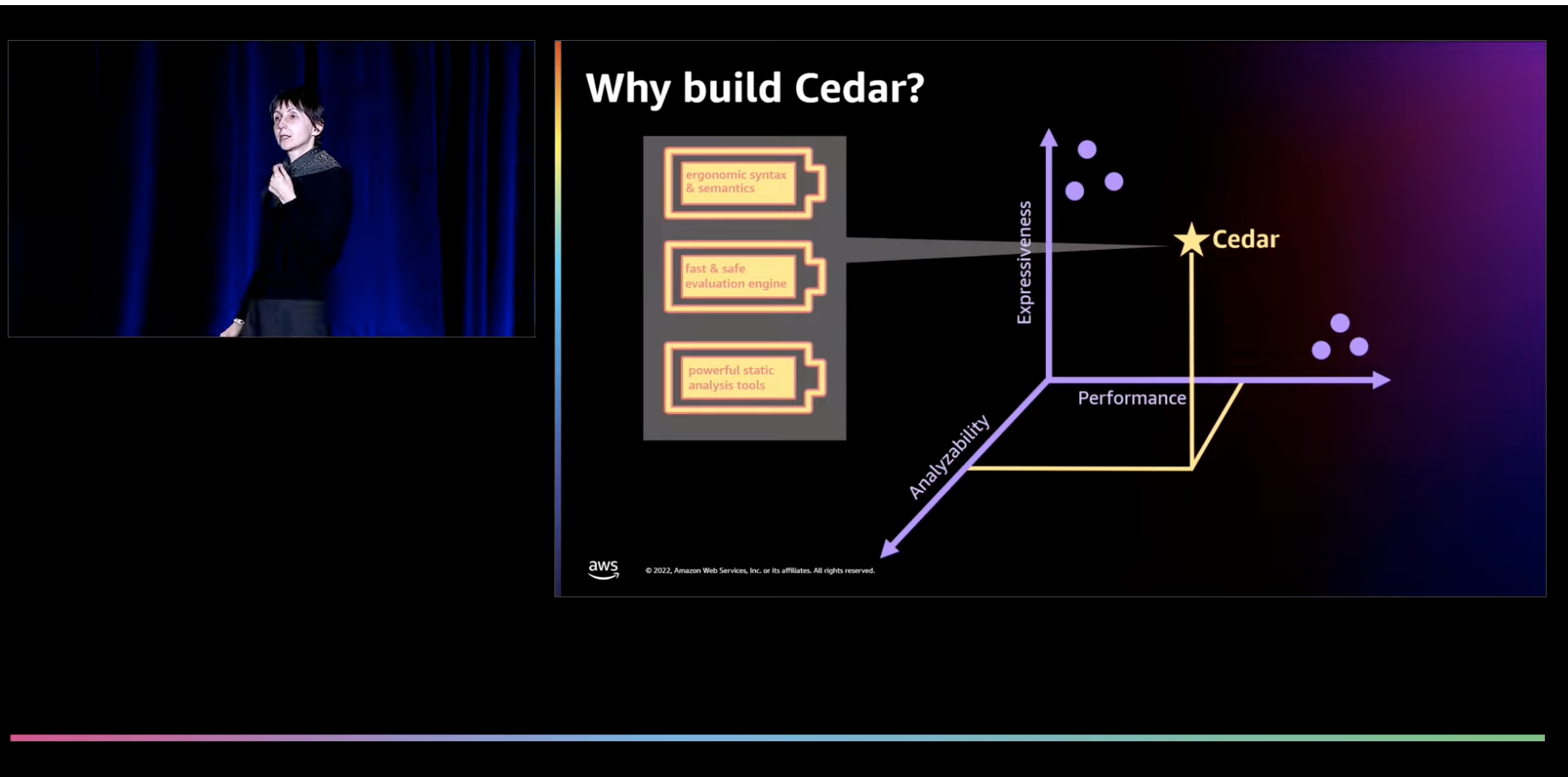
- June 12, 2023 - Why was Cedar created?
Design History
These blog posts share details about the language design and answer frequently asked questions.
Why was Cedar created?
When Cedar launched in 2022, one of the common questions we received was "Why?". After all, there was no shortage of existing authorization grammars at the time. Creating another was not the initial intent. Yet, as we evaluated options, we struggled to find one that met our needs. This eventually informed the decision to create a new language and established its guiding principles.
To frame the context, Cedar was originally developed in AWS to support services such as Amazon Verified Permissions and AWS Verified Access. Like most cloud offerings, our services typically share common characteristics which we wanted to hold true for authorization solutions, as well. Cloud services tend to be multi-tenant and seek to provide a high quality of service for all customers. If an individual authorization rule can take excessive time to run, or consume excessive system resources, this works against the quality of service goals for customers and was a behavior we sought to avoid in an authorization grammar. Cloud services also run at high scale and callers want them to behave flawlessly, making efficiency and correctness an important consideration. In terms of security, our authorization rules would be written by external customers and evaluated by the cloud service, making policies a form of untrusted code that needed to be evaluated safely. Lastly, we wanted the policy language to be understandable by a broad range of customers, and to allow for robust analysis of existing rules and the potential impacts of changing them.
All these criteria - performance, correctness, safety, analyzability – serviced as guideposts to the design of Cedar. While not all users will find themselves operating services at the same scale, we believe the criteria this demands are broadly beneficial in all domains.
In discrete terms, Cedar was designed to provide the following properties.
Bounded Latencies
Cedar is designed to make sub-millisecond authorization decisions for typical situations, regardless of the skill level of the policy author. No Cedar operators can result in blocking operations, non-terminating loops, or severe performance degradations.
No Sandboxing Required
In a high TPS system, the overhead of sandboxing every authorization decision would be impractical. Cedar policies are designed to be safely evaluated without security sandboxing, even if written by untrusted actors. Cedar contains no file system accessors, system calls, or networking operators.
Default-Deny and Order-Independent Evaluation
The Cedar evaluator will deny by default unless there exists at last one matching permit statement and no matching forbid statement. This evaluation criteria is designed to be simple, safe, and robust, and is not reliant on policy evaluation order.
Alternative authorization systems have sometimes offered more flexibility over the evaluation logic, including custom rules on policy precedence and override behavior. In recent years, there has been a general industry recognition that complexity in the human/technology interface is often a primary origin of security risk. In other words, people make mistakes, people get confused, and people click buttons to make something work without understanding why. Cedar adheres to a philosophy that a single safe-by-default evaluation mode is a preferred approach.
Ergonomic Syntax
Cedar is designed to be understandable by a broad audience. One of the design goals was that anyone should be able to read a Cedar policy and generally understand what it does without having any prior familiarity with the Cedar language.
In terms of writing policies, our design goal was that anyone with a technical skillset on par with writing SQL statements should be able to author Cedar policies. In addition, by including schema files, we wanted to make it possible to validate policies for correctness and to open the door to advanced editing capabilities such as autocompletion and more.
Support For Various Authorization Approaches
A number of well-known authorization patterns have developed over time, including RBAC, ABAC, and newer approaches such as ReBAC. All are useful in various circumstances and we didn't want to preclude customers from choosing an approach that worked best for them. Cedar is designed to support all well-known authorization patterns, and even allows them to be used in combination.
Verification-guided Development
In recognition of the important security role that Cedar plays, we wanted confidence that authorization decisions would be correct. To achieve this, we followed an approach we call verification-guided development. This approach uses automated reasoning and random differential testing to provide a high degree of trust in the implementation. My teammate Mike Hicks describes this approach in more detail in his blog post.
Amenable to Automated Analysis
Writing a policy is often the easiest part of an authorization solution. The more difficult part can be understanding what the current policies do, predicting the impact of a change, and proving to auditors that policies are correct.
Cedar was designed to support automated reasoning over a body of policies in order to enable provable assertions about system behavior.
Creating a language that is amenable to automated reasoning requires careful decision making about the supported data types and operators, as the technique relies on symbolic evaluation that considers every possible path through the code. The challenge is to keep paths sufficiently bounded so that reasoning over language statements remains tractable. For example, unbounded loops lead to an infinite, intractable number of possible paths. Even something as simple as choosing between sets vs. lists can have ramifications, as lists require the reasoning tools to consider the order that something appears and whether there can be more than one occurrence in the list, whereas sets do not. As a result, sets are more tractable for analysis. (Cedar only supports sets.)
Scalable to Large Numbers of Policies
When a system contains only a small number of authorization policies, deciding which policies to include in an authorization evaluation is a trivial matter; you can simply evaluate them all. However, as a system scales up to hundreds, thousands, or even millions of policies in a multi-tenant system, it is no longer practical to load all policies into memory to make an individual authorization decision. A more finely-tuned mechanism is required to determine which policy statements are relevant to a particular authorization query and which can be safely ignored. Cedar was designed to support this capability with a well-defined policy structure that includes a header designating the scope of the principals and resources to which a policy applies.
Striking the Right Balance
All these goals presented constraints that needed to be weighed against solving real-world authorization scenarios. After all, a robust authorization solution that can solve no real-world problems has a slim chance of adoption. Cedar's aim was to strike that balance, residing in a design space that is flexible enough for most scenarios, but structured enough to deliver the other goals.
For audiences interested in learning more, my teammate Emina Torlak presented this 23 minute session which dives deeper into the language design and syntactical choices of Cedar.
https://www.youtube.com/watch?v=k6pPcnLuOXY&t=1779s
Why doesn't Cedar have regexes or string formatting operators?
Cedar's design methodology is underpinned by a philosophy of safety, as described in "Why was Cedar created?". Safety considerations are wide-ranging and can include factors such as preventing excessive resource consumption, preserving the ability to analyze polices for correctness, or simply guiding policy authors away from common logical mistakes.
Regular expressions and string formatting operators were intentionally omitted from the language because they work against these safety goals. This blog post describes why they can be dangerous and alternative approaches to writing policies without them.
These operators are error-prone (and impolite to policy authors)
As an example, consider an authorization policy that wants to make decisions based on a URL and query string received by a web application. A naïve way to do this is to pass the entire URL as a string into the context of the policy evaluator:
"context": {
"url": "https://example.com/path?queryParam1=hello&queryParam2=world"
}
If the policy author wanted to make decisions based on subcomponents of the URL, such as the host name or particular query parameters, the policy author might need to apply regexes to match the subcomponents.
forbid (principal, action, resource)
unless {
context.url.matches("^http(s?)://example.com/")
};
They would also need to use string formatting operators to normalize the values appropriately. Normalization is important because fields such as host are case-insensitive, and a malicious actor could potentially subvert an authorization rule by sending an HTTP request with different capitalization.
forbid (principal, action, resource)
unless {
//Lowercase the hostname before matching, otherwise a caller
//could bypass this policy by sending https://EXAMPLE.COM/
context.url.toLowerCase.matches("^http(s?)://example.com/")
};
But, how should policy authors handle the query parameters? Are those case-insensitive or not? Do they have other normalization requirements? And, if so, how would the policy author know? These are application-specific details.
forbid (principal, action, resource)
unless {
// Should this also match "HELLO" or "Hello"?
context.url.matches("[&\?]queryParam1=hello[&\b]")
};
Shifting this burden onto policy authors who may not deeply understand the application details is error-prone. It is also impolite and wasteful, since many different policy authors are bearing the burden of implementing the potentially complex logic. Cedar's philosophy is that application owners should strive to format and normalize data before passing it into the authorization evaluator. This keeps the logic with the owners who have the most domain expertise, and centralizes it in one location so it can benefit all policy authors.
From this perspective, the URL information could be passed into the evaluator in a pre-normalized format such as the following:
"context": {
"url": {
"protocol": "https",
"host": "example.com",
"path": "/path",
"queryParams" {
"queryParam1": "hello",
"queryParam2": "world"
}
}
}
And a policy author could express rules such as the following:
forbid (principal, action, resource)
unless {
context.url.host == "example.com"
};
Another reason that regular expressions are error-prone is because of human error. To provide a real life example shared with me by a teammate, a policy author (in a non-Cedar system) wanted to write a rule that allowed anyone in the "admin" group to have super-administrator privileges in an application. This was done by examining a user's list of groups and testing against the regex /admin/. The mistake was not including the word-boundary conditions in the regex, such that this rule accidentally matched the group "administrative-assistants" and theoretically, I guess, the "badminton-club". The administrative assistants discovered this access and found it quite useful in getting their job done.
Regular expressions and string formatting operations are powerful features that are useful in many programming environments. However, in authorization rules that protect access to critical resources, Cedar takes the perspective that simple, safe, auditable rules are preferrable over unbounded flexibility.
These operators are subject to runtime risks
Regexes and string formatting operations carry runtime risks, as well. Regexes are subject to poor performance characteristics, including worst-case scenarios such as catastrophic backtracking. String formatting operations can also be abused. To provide an example, consider an operator that concatenates two strings and emits a new string.
new_string = concat(string1,string2)
Presuming the input strings are well-bounded in size, this operator is safe when used once. But, what happens if string concatenations are nested?
concat( concat(x,x), concat(x,x))
If x="hello", this concatenates the string "hello" repeatedly
hello
hellohelllo
hellohellohellohello
A malicious policy author could push this to an extreme:
concat( concat( concat( concat( concat( concat(x,x), concat(x,x)), concat(concat(x,x), concat(x,x))), concat( concat( concat(x,x), concat(x,x)), concat(concat(x,x), concat(x,x)))), concat( concat( concat( concat(x,x), concat(x,x)), concat(concat(x,x), concat(x,x))), concat( concat( concat(x,x), concat(x,x)), concat(concat(x,x), concat(x,x))))), concat( concat( concat( concat( concat(x,x), concat(x,x)), concat(concat(x,x), concat(x,x))), concat( concat( concat(x,x), concat(x,x)), concat(concat(x,x), concat(x,x)))), concat( concat( concat( concat(x,x), concat(x,x)), concat(concat(x,x), concat(x,x))), concat( concat( concat(x,x), concat(x,x)), concat(concat(x,x), concat(x,x))))))
Due to the power of exponential growth, it would take only 40 repetitions of concatenation to transform the word "hello" into a 5 terabyte string that exceeds the available memory on nearly all classes of modern, general purpose web servers. To provide bounded runtime latencies, an authorization engine would need to guard against excessive memory allocation and fail at runtime. This requires a degree of guesswork about how much memory is "too much", with a risk of that choice being either too high or too low for someone's legitimate situation.
These operators are not analyzable
As described in Why was Cedar created?, the language was built using verification-guided development and designed for automated reasoning. These techniques provide two benefits: they give a high-degree of confidence that Cedar is implemented correctly (i.e. bug free), and they also allow analyses in order to give you confidence that the policies you write in Cedar are correct.
Regular expressions and many string formatting operators are not amenable to these formal reasoning techniques. As a result, these operators simultaneously increase the likelihood of end-user mistakes when writing policies, while at the same time lessening Cedar's ability to alert users of these mistakes.
Alternative Approaches
As mentioned earlier, the most common approach is to pre-format data before passing it into the authorization evaluator, thereby freeing policy authors from the need for regular expressions and string formatting operations.
When this is insufficient, the Cedar team is interested in hearing the requirements. (You can reach the community on the Cedar Slack channel.) Although Cedar is strict in terms of safety, it is also pragmatically motivated to solve real-world scenarios. Quite often, alternative approaches can be found that address requirements while adhering to safety goals. For example, Cedar includes a like operator with wildcard matching, which solves many situations that would otherwise require regexes. Cedar also supports extended datatypes for fields such as IP Address, with built in validation and helpful operators that can be used in policy expressions. Additional extended datatypes can be introduced if they have broad applicability.
Why doesn't Cedar support floating point numbers?
Sometimes, it's necessary to write an authorization rule against numbers that contain decimal parts. For example, you may want to check if a currency field is greater than "1.99", or compare the output from an ML-based risk scoring system which emits values such as "0.9234". Cedar supports this using the Decimal type with a fixed precision, where the maximum number of digits after the decimal is four.
In many other programming environments, there is an alternative representation of numbers known as floating-point which allows for bigger or smaller values with different degrees of precision. For example, a floating point number might approximate the value of pi with a sequence of digits such as "3.141592653589793…" up to the maximum size allowed by the data type, often 64 bits or 15 decimal digits.
Cedar does not support floating-point numbers. The reason is because floating-point numbers, by their nature, are imprecise, and imprecision is not a desirable property of an authorization system. To illustrate this point, consider the following test: 0.1 + 0.2 == 0.3. This appears as if it should evaluate to true. But, in most programming languages, it doesn't. This blog post documents the result of the operation in a variety of different programming languages. The reason this occurs is because fractions such as 1/10 and 1/20 do not have a precise binary representation. Floating-point arithmetic approximates these values with a limited degree of precision.
Floating-point can lead to other quirks as well. For example 262144.0 + 0.01 = 262144.0. One number plus another number equals the same number. You can see a similar effect in Javascript by taking the number 16128500101100052000 and adding 1; you get the same number back. (Javascript number are always 64-bit floating-point). This behavior occurs when adding large and small numbers. An excellent blog post describes these quirks of floating-point and real world impacts.
Floating-point is a well-defined and a very useful format in many other programming contexts. We elected not to include it in Cedar not because it’s a “bad” format, but because we think it’s a bad idea to use this kind of arithmetic for authorization decisions.
Because of this, Cedar also does not include mathematical operators such as division that return floating-point values. For example, the operation 1 / 3 would necessitate a floating-point value for the result. Cedar also does not allow multiplication with Decimal types, such as 1 * decimal("0.3"), as this would lead to the same outcome.
For additional information on the Cedar Decimal type and other operators, see the documentation. Decimal supports the following operations:
decimal("0.3") == decimal("0.3") //true
decimal("0.3") != decimal("0.4321") //true
decimal("0.3").lessThan("922337203685477.5807") //true
decimal("0.3").lessThanOrEqual("0.300") //true
decimal("0.3").greaterThan("-4.82") //true
decimal("0.3").greaterThanOrEqual("00.30") //true
Why doesn't Cedar allow wildcards in Entity Ids?
TLDR: This can be a risky anti-pattern. This post explains the risks and how to accomplish it when absolutely necessary.
Cedar supports wildcards for string matching via the like operator. However, wildcards are not allowed for Entity Id matching. Before explaining why, the question itself deserves explanation as not everyone will necessarily understand why someone would want wildcard matching in Entity Ids.
For those new to Cedar, Entity Ids are the means to refer to a specific principal or resource within a policy statement. Examples may look like this:
permit (
principal == User::"5fb883fb-229c-48bc-b186-e7ed9074b536",
action,
resource == File::"8d60e1b7-ed63-419b-b198-13ac9e803ee7"
);
The fields labeled "User" and "File" are the Entity Ids. They consist of a type like User, plus an identifier like 5fb883fb-229c-48bc-b186-e7ed9074b536.
In this example, we have used UUIDs as the identifiers. Synthetic identifiers are recommended by the Cedar Security guidance. When using synthetic identifers, the benefits of wildcards may not be readily apparent. After all, trying to match against a pattern such as User::"5fb883*4b536"is unlikely to be useful in practice.
Therefore, questions about wildcard support most often arise in situations where the Entity Id is not synthetic, but rather a string that encodes information about the system. For example, the identifier might be a path that describes a hierarchical nesting of resources:
File::"/Org:923902/Department:4992/Folder:MonthlyReports/January2023.pdf"
If wildcards were allowed by Cedar, then access to all folders for a specific department could be represented by using a wildcard in the identifier, as follows:
permit (
principal == User::"5fb883fb-229c-48bc-b186-e7ed9074b536",
action,
resource == File::"/Org:923902/Department:4992/*"
);
Another situation where identifiers can encode information is when they include metadata, such as the owner of the resource:
File::"user:32432423/image123.jpg"
File::"user:32432423/image456.jpg"
In this example, each file name is prepended with the userId of the owner, and someone can be granted access to the files they own via a policy such as:
permit (
principal == User::"5fb883fb-229c-48bc-b186-e7ed9074b536",
action,
resource == File::"user:32432423/*"
);
Lastly, the goal may be to match any identifer of a particular type:
//Allow any User to read any File
permit (
principal == User::"*",
action == Action::"readFile",
resource == File::"*"
);
This last pattern is about testing the type of an entity. It is best addressed by a new operator named is which is under discussion in RFC 0005 and does not require wildcards. Hence, the remainder of this post will focus on the previous cases.
Security Considerations
As alluded to earlier in this post, embedding system information into identifiers is against the Cedar Security guidance. Here's an extract from the guidance:
Use unique, immutable, and non-recyclable IDs for entity identifiers….
There are a class of authorization vulnerabilities that arise from not following this guidance. One of the impacts occurs when an identifier is recycled. For example, if access is granted to a customer named User::"alice", and then Alice departs and a new customer acquires the same username User::"alice", then the new user gets access to everything granted by policies that still reference User::"alice".
Another subtle vulnerability occurs when identifiers require normalization. For example, consider the identifier we observed previously:
File::"/Org:923902/Department:4992/Folder:MonthlyReports/January2023.pdf"
What would be the impact if the filesystem was case-insensitive?
// All these identifiers resolve to the same resource
File::"/Org:923902/Department:4992/Folder:monthlyreports/january2023.pdf"
File::"/Org:923902/Department:4992/Folder:MonthlyReports/January2023.pdf"
File::"/Org:923902/Department:4992/Folder:MONTHLYREPORTS/JANUARY2023.pdf"
Imagine if the file was retrievable via an HTTP request to a web application:
GET https://example.com/Org_923902/Department_4992/Folder_MONTHLYREPORTS/JANUARY2023.pdf
If the application forgot to normalize the filename it received in the HTTP request prior to authorization, then the following rule could be bypassed by the caller simply by using different capitalization:
// UH-OH: This forbid rule won't work when is_authorized()
// is invoked with an uppercase version of the filename.
forbid (
principal == User::"5fb883fb-229c-48bc-b186-e7ed9074b536",
action,
resource == File::"/Org:923902/Department:4992/Folder:MonthlyReports/January2023.pdf"
);
Other side-effects of poorly-formed identifiers include the following nuisances:
| Id Style | Impact |
|---|---|
User::"alice" | Alice can't change her username without re-creating all policies |
File::"user:12354323:image.jpg" | File can't be assigned to a new owner without re-creating all policies |
File::"folder:VacationPhotos/image123.jpg" | File can't be moved to a new Folder without re-creating all policies |
In summary, prefer to use synthetic identifiers (such as UUID) whenever feasible. If this security guidance is followed, then wildcards in the Entity Id provide little value. Cedar offers alternative, more robust mechanisms to deliver the same capabilities that the wildcards were providing. For example, Cedar has built-in support for hierarchical relationships, so these don't need to be embedded in the identifier. Cedar also has built-in support for attribute-based access controls, so concepts such as "owner" don't need to be embedded in the identifiers.
But, what if I still need wildcards?
Despite the security guidance, there may be situations when non-synthetic identifiers are unavoidable. This could occur, for example, if identifiers are constructed by an external system outside the control of the application owner. If security risks are acknowledged and mitigated, and the situation is unavoidable, then there can be a legitimate need to perform wildcard matching on the identifier.
Cedar allows wildcard matching in the policy conditions:
// Valid Syntax
permit (
principal == User::"5fb883fb-229c-48bc-b186-e7ed9074b536",
action,
resource
) when {
resource.id like "*part1*part2*" // <-- Wildcards are allowed in policy conditions.
// See discussion at end of blog post for
// more details on the "id" field.
};
But, Cedar blocks this in the policy scope:
// ERROR. Invalid Syntax
permit (
principal == User::"5fb883fb-229c-48bc-b186-e7ed9074b536",
action,
resource == File::*part1*part2*" // <-- Wildcards prohibited in policy scope
);
The real question is therefore: why does Cedar prohibit wildcards in the policy scope, but allow them in the conditions? The reasoning rests on understanding why the policy scope is special, and the tradeoffs of using wildcards.
The policy scope defines where a policy is "attached", meaning whether it applies to a single resource, a predefined group of resources, or perhaps any resource where certain conditions are met. The more narrowly defined the policy scope can be, the more efficient a system can perform in terms of policy storage, retrieval, and evaluation. This is an important consideration as the number of policies in a system increases.
When policies are "attached" to a specific resource or resource-group, this also enables different types of authorization queries such as "list all the resources a principal can access".
Using wildcards in an entity identifier is equivalent to saying "I don't know exactly which resource this will apply to, but it should match any resource where the identifier value satisfies a set of conditions". This is attribute-based access control (ABAC), which must be represented in the Cedar conditions. The reasoning for this is described by my teammate Emina Torlak in her talk.
Performance and Scaling Considerations
Something to be aware of when using lots and lots of ABAC policies modeled in this way, where a resource is unspecified in the policy scope, is that you may see performance linearly slow as the number of policies increases. This is because there is no shortcut to ignore the policy. Each one must be evaluated, because each policy could potentially match any resource; we don't know for sure until the conditions are evaluated.
Another consideration is that hosted storage solutions will often place limits on the total amount of policies that can be stored for an unspecified value of resource. For example, at the time of this writing, Amazon Verified Permissions will allow a maximum of 200,000 bytes.
Lastly, by not specifying a specific resource identifier in the policy, it is no longer feasible to answer the question "What resources can a principal access?" by examining the policies, because the information isn't in the policies. The best that Cedar could answer is the conditions under which a resource is accessible.
All of these tradeoffs are inherent to any ABAC approach. ABAC is a powerful and useful tool, though it has impacts worth understanding.
Therefore, the reason Cedar only allows wildcards in the conditions is to make it clear there is no magic. Wildcards result in an ABAC-style policy with all the same tradeoffs and considerations as any other ABAC policy.
In summary, blocking wildcards in the policy scope is Cedar's way of nudging end-users toward best practices that result in the best security, the best scaling, and the most features, while at the same time allowing an escape-valve via ABAC conditions for the less common situations that require it.
Related Issues
The solution described above relies an attribute on the resource named id:
permit (
principal == User::"5fb883fb-229c-48bc-b186-e7ed9074b536",
action,
resource
) when {
resource.id like "*part1*part2*" // <-- Matching on "id" attribute
};
The id field is not a built-in property provided by Cedar. It is simply an attributed named "id" (or whatever you want to call it) that is manually populated by the application owner. The drawback of this approach is that it requires the identifier to be copied into a second place to write conditions against it. To make this easier and more syntactically pleasing, there is currently an open GitHub issue proposing a syntax that just works without the extra copying.
permit (
principal == User::"5fb883fb-229c-48bc-b186-e7ed9074b536",
action,
resource
) when {
resource like File::"image*.jpg"
};
At the time of this writing, this issue is still under discussion.
Why does Cedar ignore policies that error?
When asking Cedar to make an authorization decision, it is possible for an error to occur. Consider the following example:
permit (
principal,
action == Action::"read",
resource in Folder::"financial_reports"
) when {
principal.jobRole == "Finance"
};
If the value of principal.jobRole is undefined, this will cause an error during evaluation and Cedar will ignore the policy, treating the situation as if the policy never existed. Cedar will then continue evaluating the other policies to make a final authorization decision. Other situations can cause errors, as well, and they can be found by searching for "error" in the Cedar operator documentation.
This behavior can lead to the questions:
- Why does Cedar generate an error?
- And, why does it ignore a policy if it errors?
Why does Cedar generate an error?
The decision to generate an error may appear unnecessary at first, especially if there are multiple conditions as in the following example:
permit (
principal,
action == Action::"read",
resource in Folder::"financial_reports"
) when {
principal.jobRole == "Finance" ||
principal.jobLevel > 10
};
In this example, if principal.jobRole was undefined but principal.jobLevel was defined, it would be convenient for the policy to not error. The second condition would match and everything would proceed happily.
Implementing this behavior would require treating the undefined attribute as some type of nil value. Any operation on this value, such as an equality check, would evaluate to false. This could be done, but it has a side-effect when negations are introduced:
// Permit anyone to read the folder UNLESS their job role is "external_contractor".
permit (
principal,
action == Action::"read",
resource in Folder::"financial_reports"
) when {
!( principal.jobRole == "external_contractor")
};
In this example, if a missing value of principal.jobRole was treated as a nil type, then the expression would surprisingly permit access. This is because nil == "external_contractor" would evaluate to false. But, since this is negated, the false becomes true.
As a result, anyone with an undefined value of jobRole gets access to the resource. Is this desired behavior? Is it undesired? The answer is indeterminate and therefore Cedar errors. Only the policy author can resolve the ambiguity. If the author had used the Cedar validator, this policy would have been flagged as a potential error. To fix the error, the policy author can amend the conditions to test if the optional attribute exists before using it.
// Permit anyone to read the folder UNLESS their job role is "external_contractor".
permit (
principal,
action == Action::"read",
resource in Folder::"financial_reports"
) when {
principal has robRole &&
!( principal.jobRole == "external_contractor")
};
Why does Cedar ignore policies that error?
When a policy errors, Cedar could halt and default the authorization decision to Deny instead of ignoring the error and proceeding to evaluate other policies. The reason it doesn't halt is for the safety of applications using Cedar. Imagine a system with 100 policies that are running successfully, and then someone adds policy number 101 which contains an error. If Cedar halted on error and emitted a default-deny decision for the entire batch of policies, then 100% of all authorization decisions in the system could begin failing, simply because someone introduced an error in one new policy.
If ignore-on-error behavior is worrisome to you, note that the Cedar evaluator returns diagnostics that indicate if any policies emitted errors. System owners may use this field to monitor for errors or even choose to fail-closed on error, if desired.
What about forbid statements?
It is relatively safe to ignore permit statements that error since the impact is to allow less access; something that was intended to be permitted is not permitted. However, the inverse happens when ignoring a forbid statement; something that was intended to be forbidden may not be forbidden.
One of the larger debates during Cedar's design was whether errors in forbid statements should result in a policy being skipped, same as permit statements. The arguments on one side say it feels safer from a security perspective to behave differently and return a Deny decision when a forbid statement emits an error. At the same time, this has to be weighed against the blast impact of a mistake in a single policy resulting in 100% of all authorization queries returning a Deny decision. This behavior could lead to 100% unavailability for an application, which is also a goal of many types of attacks.
In the end, this was a debate with no winning side. The reality is that forbid statements are powerful, and anyone deploying forbid statements to production with zero testing beforehand is likely to have a bad day either way. As a result, Cedar behaves consistently - an error in any policy statement, whether permit or forbid, will result in the policy being skipped during an authorization evaluation. To minimize risk, Cedar policy validation can detect policy statements that may error at runtime so they may be corrected before being used in production. In addition, some authorization systems go further by allowing shadow testing of new policies to audit for unexpected behaviors prior to enforcement. On top of this, Cedar returns diagnostics in the authorization response that indicates if errors occurred. This can be used to monitor for new errors that may arise after a policy is deployed. Or, if desired, system owners may use these diagnostics to observe when an error occurred in a forbid statement and can elect to treat that as a fail-closed scenario, if appropriate for their application.
Why do Cedar policies end with a semi-colon?
At one time or another, we all forget to include the semi-colon at the end of a policy statement. This can lead to the question: why is it there?
// Sample Policy
permit (principal, action, resource)
when {
principal == resource.owner
};
The semi-colon is not needed for parsing. In fact, early prototypes of Cedar didn't include it. The reason it's there is for safety. Consider what would happen if the example above was accidentally truncated after the first line and a semi-colon wasn't required.
permit( principal, action, resource)
In such a scenario, this would be a valid statement. It allows "any principal" to perform "any action" on "any resource". In other words, the system has failed-open because of a truncation mistake. The semi-colon protects against truncation errors.
Now, you might say this feature needn't be baked into the Cedar grammar. After all, it could be the responsibility of everyone who is storing or transmitting policies to sign them or include a checksum, and to enforce that upon receipt to detect accidental truncation. For anyone concerned about data corruption, those remain helpful practices for any data. But, we wanted to ensure Cedar was safe by default for all audiences. And, it's not hard to imagine situations where a checksum wouldn't help at all, such as a bad copy-and-paste where the end-user forgot to highlight the entire policy and only copied a subset into a UI. The little semi-colon is the safety net to catch such mistakes.
Cedar Usage
These blog posts share details about Cedar language usage.
How well do Cedar policies compress?
I was curious about this question as the information could be useful for scenarios ranging from storing lots of policies compactly to injecting a single policy into a space-constrained bearer token. The hunch was that Cedar policies would compress well due to the fixed structure of the language. After all, most policies start with the same 20 characters: "permit (principal == ".
There will never be an absolute answer since compression rates vary by policy contents. After all, one could add a 10MB randomly-generated string into a policy and the compression rates would fall off a cliff, regardless of the algorithm. Nevertheless, ignoring pathological scenarios, I wanted to know the order of magnitude that one might expect from common cases. So, I spent an afternoon running a few experiments.
The answer, of course, is "it depends". The space savings ranged from 17% to 90%. But, it's fair to say that for files containing more than 50 policies, the space saving is likely to be over 80%. (Bigger is better for this number; 80% means a 10MB file would compress to 2MB.)
The remainder of this post describes the methodology and details.
Experiment 1: More than 100 policies
I wrote a short program to randomly generate RBAC & ABAC style policies with varying conditions. To make it as unfair as possible, I used randomly generated strings for attribute names and values. In real life, most attribute name/value pairs are likely to be dictionary words, such as "location": "Seattle", which may improve compression rates. But, I wanted to be pessimistic.
The first experiment used zlib with default settings. I compressed files of 10K, 1K, and 100 policies where the policies were either pure RBAC, ABAC, or a mix. Here's the resulting space savings:
| RBAC | ABAC | Mix | |
|---|---|---|---|
| 100 Policies | 81% | 87% | 82% |
| 1000 Policies | 82% | 90% | 85% |
| 10,000 Policies | 82% | 90% | 86% |
As the table shows, all compression rates were between 80-90%. ABAC fared slightly better, likely because all the policies started with:
permit (principal, action, resource) when {
followed by conditions using common keywords like principal, resource, and context.
RBAC fared slightly worse, likely because of the random UUIDs sprinkled throughout.
permit (
principal == ExampleApp::User::"a8e37111304143ae9cd75bf2625aa4ac",
action in [
ExampleApp::Action::"fvasthxzcm",
ExampleApp::Action::"rrgoxrwupc",
ExampleApp::Action::"ktjytscfvp"
],
resource == ExampleApp::Resource::"daffb6288dfb4bb5a0c4df4de7ca76ba"
);
I tried a few variations that toggled zlib's configuration between fast vs. best compression, and while it varied the results by small percentages, everything stayed in the 80-90% band.
Experiment 2: Fewer than 100 policies
Compression rates are expected to worsen with smaller data and the subsequent experiments confirmed that. A single ABAC policy compressed by merely 17%. A single RBAC policy fared better at 44%, likely assisted (as seen in the example above) by repetitive tokens such as ExampleApp::Action::
Between 1-100 policies was an inflection point. I iterated across that range to find the trends. Here's the results.
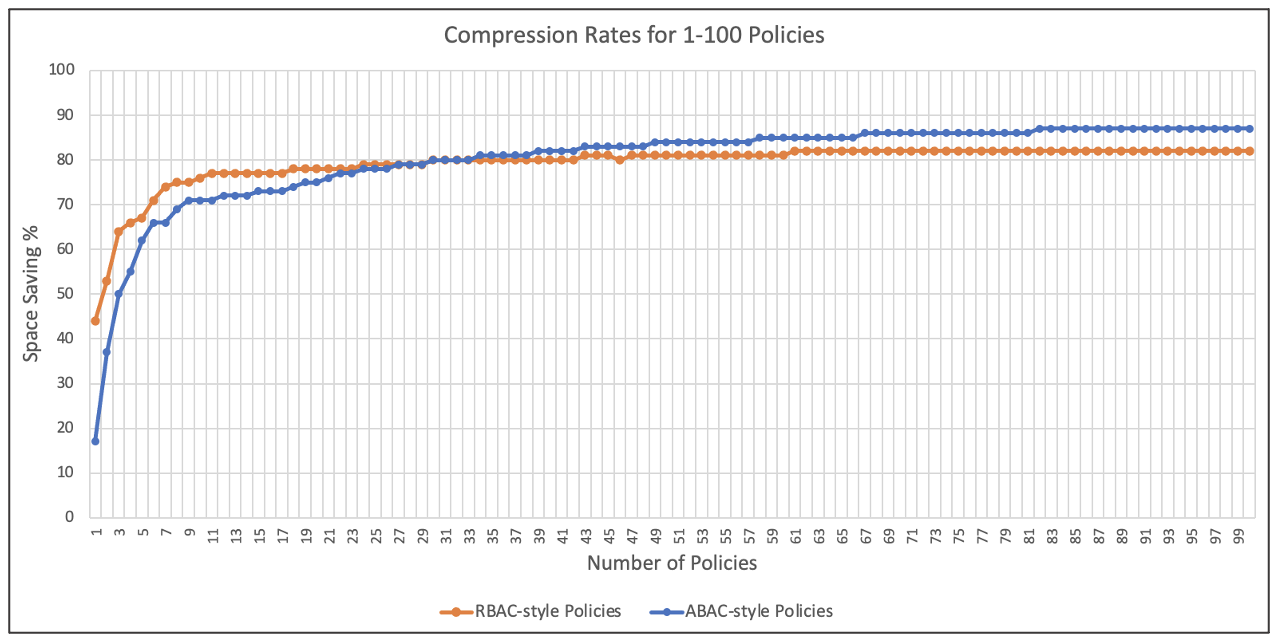
As it shows, having at least 10 policies is sufficient to gain a 70% space saving, and having 40+ is sufficient to deliver 80%.
Fewer than 5 policies led to a precipitous drop and highly variable results that depended on the repetitiveness within the policies themselves. For example, a single RBAC policy with a long list of ExampleApp::Action:: elements might compress by half due to the repetition of the actions, whereas an ABAC policy of equivalent length may barely compress at all.
Was it possible to make the compression rates more reliable for small numbers of policies? This led to the final experiment…
Experiment 3: Using a Pre-built Dictionary
Instead of using zlib, the alternative ZStandard compression utility makes it easy to pre-generate a dictionary from training data that can be used to improve the results when compressing small datasets. This is helpful because we know that all Cedar policies will contain similar elements, such as starting with "permit (principal ==". If this knowledge can be predefined in a dictionary, then compression activity can use that fact even when operating upon a single policy.
To setup this experiment, I generated training data consisting of 10K random policies with a mixture of RBAC and ABAC, and then used the zstd tools to generate a dictionary and run another series of benchmarks.
The results: the compression ratio for a single ABAC policy increased from 17% to 56%. And, an RBAC policy increased slightly from 44% to 48%.
Once the number of policies increased to 5, results were on par with those from zlib. So, on the whole, a pre-built dictionary helped push the compression rate up to ~50% when compressing 1-2 policies, and had little effect beyond that. Advanced dictionary tuning may increase that further, but doing so was beyond the scope of this simple series of experiments.
Takeaways
With maximal laziness, using default compression settings, we might expect a space savings of 80-90% for 100+ policies. For a smaller number of policies, a pre-built dictionary could help deliver a lower bound of ~50% compression with minimal effort, and possibly more with extra dictionary tuning.
Note that tests were run using policies that shared uniform formatting and no inline comments. The addition of random whitespace and comments into Cedar policies, as might be expected if humans were writing them, could dampen the rates. Therefore, stripping comments and re-formatting policies could be a beneficial prerequisite to compaction. These tests also relied upon synthetic data that may deviate from real-world policies, so mileage may vary.
As an alternative approach to reducing policy size, another idea that occasionally arises is the ability to pre-parse and pre-compile Cedar policies into a byte-code representation. This would have the effect of both shrinking the overall size and also lowering the evaluation cost, since policies arrive pre-compiled and ready to go. Therefore, if future scenarios arise where it would be beneficial to pack a small number of policies as tightly as possible (such as in bearer tokens), efforts might best be directed towards a Cedar byte-code representation instead of clever compression dictionaries. This path would deliver a more reliable win all-around and provide benefits to anyone who wants to reduce evaluation costs, regardless of the number of policies.
A Quick Guide To Partial Evaluation
I am pleased to share this guest post by Aaron Eline, my teammate and one of the implementors of Cedar partial evaluation. If you'd like to chat further about any of the features described in this post, join us in the Cedar Slack channel. -Darin
Enabling partial evaluation
Partial evaluation is released as an “experimental” feature. This means two things
- We don’t have a formal model or proof of correctness
- We expect the API to change somewhat as customers experiment with the feature. (This means we welcome feedback!)
To enable partial evaluation, let’s start a new cargo project with the following Cargo.toml
[package]
name = "pe_example"
version = "0.1.0"
edition = "2021"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
cedar-policy = { features = ["partial-eval"], version = "3.0" }
This enables the partial-eval experimental feature.
Using partial evaluation
Partial evaluation exposes one key new function on the Authorizer struct: is_authorized_partial. ( source) This takes the same arguments as is_authorized, but has a different return type. Where is_authorized is guaranteed to always return either Allow or Deny, is_authorized_partial can return Allow, Deny, or a “residual”: the set of policies it was unable to evaluate.
A quick demo
Let’s create a quick demo application that reads a policy set and context off of disk and attempts to authorize:
use cedar_policy::{PolicySet, Authorizer, Request, Context, Entities}; use std::io::prelude::*; fn main() { let policies_src = std::fs::read_to_string("./policies.cedar").unwrap(); let policies : PolicySet = policies_src.parse().unwrap(); let f = std::fs::File::open("./context.json").unwrap(); let context = Context::from_json_file(f, None).unwrap(); let auth = Authorizer::new(); let r = Request::new(Some(r#"User::"Alice""#.parse().unwrap()), Some(r#"Action::"View""#.parse().unwrap()), Some(r#"Box::"A""#.parse().unwrap()), context, None).unwrap(); let answer = auth.is_authorized(&r, &policies, &Entities::empty()); println!("{:?}", answer); }
Let’s try it with a simple policies.cedar :
permit(principal,action,resource);
and the empty context in context.json:
{}
Running it, we see:
aeline@88665a58d3ad example % cargo r
Compiling example v0.1.0 (/Users/aeline/src/example)
Finished dev [unoptimized + debuginfo] target(s) in 0.54s
Running `target/debug/example`
Response { decision: Allow,
diagnostics: Diagnostics { reason: {PolicyId(PolicyID("policy0"))},
errors: {} } }
We get Allow, as expected, since the policy should match anything. Let’s try now by changing the line with is_authorized to use is_authorized_partial :
let answer = auth.is_authorized_partial(&r, &policies, &Entities::empty());
Running it:
aeline@88665a58d3ad example % cargo r
Compiling example v0.1.0 (/Users/aeline/src/example)
Finished dev [unoptimized + debuginfo] target(s) in 0.56s
Running `target/debug/example`
Concrete(Response { decision: Allow,
diagnostics: Diagnostics { reason: {PolicyId(PolicyID("policy0"))},
errors: {} } })
Now we get a slightly different answer, saying the evaluator was able to produce concrete answer, and that answer was Allow . There’s nothing in our policy or context that would prevent a full and concrete answer.
Our First Residual
Let’s try a new policies.cedar:
forbid(principal, action, resource) unless {
context.secure
};
permit(principal == User::"Alice", action, resource) when {
context.location == "Baltimore"
};
and context.json :
{
"secure" : true,
"location" : { "__extn" : {
"fn" : "unknown",
"arg" : "location"
}}
}
Here, we set the value of the location field to a call to the extension function unknown. unknown values are “holes” that the partial evaluator cannot further reduce, and ultimately can lead to evaluation not producing a concrete answer.
Let’s try evaluating our request with these new inputs:
aeline@88665a58d3ad example % cargo r
Finished dev [unoptimized + debuginfo] target(s) in 0.15s
Running `target/debug/example`
Residual(ResidualResponse {
residuals: PolicySet {
ast: PolicySet {
templates: { PolicyID("policy1"):
Template {
body: TemplateBody {
id: PolicyID("policy1"),
annotations: {},
effect: Permit,
principal_constraint: PrincipalConstraint {
constraint: Any
}, ....
The debug printer displays loads of unecessary information in a a hard to read format. Let’s change our code to use the pretty printer, rather than the debug printer:
#![allow(unused)] fn main() { match auth.is_authorized_partial(&r, &policies, &Entities::empty()) { PartialResponse::Concrete(r) => println!("{:?}", r), PartialResponse::Residual(r) => { println!("Residuals:"); for policy in r.residuals().policies() { println!("{policy}"); } } } }
Re-running with this new printer gives us:
Residuals:
permit(
principal,
action,
resource
) when {
true && (unknown(location) == "Baltimore")
};
We can see that the forbid policy has dropped entirely, as context.secure was fully known so we know the forbid policy doesn’t apply. On the permit policy, the head constraints have been simplified away (as principal was in fact User::"alice"). What remains is the constraint that context.location has to equal "Baltimore", plus a residual true && expression which is explained further in Caveats.
If we change our context.json to set context.secure to be false, and re-run, we get:
dev-dsk-aeline-1d-f2264f25 % cargo r
Finished dev [unoptimized + debuginfo] target(s) in 0.08s
Running `target/debug/pe_example`
Response { decision: Deny,
diagnostics: Diagnostics { reason: {PolicyId(PolicyID("policy0"))},
errors: [] } }
Now we get Deny. Even though the value of context.location was unknown, it wasn’t needed to compute the final result, as the forbid policy trumps the permit.
A simple application
Let’s use a simple document application as a demo for how one could use Partial Evaluation in a real application.
In this application there will be two kinds of entities: Users and Documents. Every document has two attributes: isPublic and owner. There are two actions: View and Delete. Requests pass a context with two values: the request’s source IP address, src_ip, and whether or not the request was authenticated with multiple factors, mfa_authed. Here are our policies for this application:
// Users can access public documents
permit (
principal,
action == DocCloud::Action::"View",
resource
) when {
resource.isPublic
};
// Users can access owned documents if they are mfa-authenticated
permit (
principal,
action == DocCloud::Action::"View",
resource
) when {
context.mfa_authed &&
resource.owner == principal
};
// Users can only delete documents they own, and they both come from the company network and are mfa-authenticated
permit (
principal,
action == DocCloud::Action::"Delete",
resource
) when {
context.src_ip.isInRange(ip("1.1.1.0/24")) &&
context.mfa_authed &&
resource.owner == principal
};
What can Alice access?
Concrete evaluation works for answering the question “Can Alice access Document ABC?”. But it doesn’t work well for answering the question “What documents can Alice access?”. Partial evaluation can help us answer this question by extracting the residual policies around an unknown resource that would evaluate to Allow, ignoring/folding away constraints that don’t matter or are common to all resources.
We’ll change our simple main to the following:
fn main() { let policies_src = std::fs::read_to_string("./policies.cedar").unwrap(); let policies: PolicySet = policies_src.parse().unwrap(); let f = std::fs::File::open("./context.json").unwrap(); let context = Context::from_json_file(f, None).unwrap(); let auth = Authorizer::new(); let r = RequestBuilder::default() .principal(Some(r#"DocCloud::User::"Alice""#.parse().unwrap())) .action(Some(r#"DocCloud::Action::"View""#.parse().unwrap())) .context(context) .build() .unwrap(); match auth.is_authorized_partial(&r, &policies, &Entities::empty()) { PartialResponse::Concrete(r) => println!("{:?}", r), PartialResponse::Residual(r) => { println!("Residuals:"); for policy in r.residuals().policies() { println!("{policy}"); } } } }
This is mostly the same as last time, but with one important difference: We’ve dropped .resource() from our RequestBuilder. This sets resource to be an unknown value.
Running this with the following context.json:
{
"mfa_authed" : true,
"src_ip" : { "__extn" : {
"fn" : "ip",
"arg" : "1.1.1.0/24"
}
}
Yields:
dev-dsk-aeline-1d-f2264f25 % cargo r
Finished dev [unoptimized + debuginfo] target(s) in 0.08s
Running `target/debug/pe_example`
Residuals:
permit(
principal,
action,
resource
) when {
true && (true && ((unknown(resource)["owner"]) == DocCloud::User::"Alice"))
};
permit(
principal,
action,
resource
) when {
true && (unknown(resource)["isPublic"])
};
Her are some interesting things about this residual set:
- The policy governing
Deleteis gone. It evaluates tofalseand so is dropped from the residual. - The constraint that
actionmust equalViewis gone from the two remaining policies, since it is alwaystruefor this request. - The constraint on
context.mfa_authedis also gone since it is alsotrue, always.
Let’s try a few more scenarios. First we’ll change our context.json to:
{
"mfa_authed" : false,
"src_ip" : { "__extn" : {
"fn" : "ip",
"arg" : "1.1.1.0/24"
}
}
Re-running:
dev-dsk-aeline-1d-f2264f25 % cargo r
Finished dev [unoptimized + debuginfo] target(s) in 0.08s
Running `target/debug/pe_example`
Residuals:
permit(
principal,
action,
resource
) when {
true && (unknown(resource)["isPublic"])
};
Now we only get the one residual policy. No matter who owns a document, principals without MFA can view only public documents.
Let’s now try changing our Action in the request (defined in main.rs) to DocCloud::Action::"Delete":
dev-dsk-aeline-1d-f2264f25 % cargo r
Finished dev [unoptimized + debuginfo] target(s) in 0.08s
Running `target/debug/pe_example`
Response { decision: Deny, diagnostics: Diagnostics { reason: {}, errors: [] } }
Now we simply get Deny! Even with the resource fully unknown, there is no way for any rule involving Delete to ever evaluate to true given our context .
What to do with the residuals?
What now? Our original goal was to answer the question: Which resources does Alice have access to? We have shown the simplified policies that would grant access to Alice, but we are not all the way there. The residual policies are essentially constraints that represent Alice’s set of viewable documents. Any document that meets those constraints, i.e., one in which replacing unknown(resource) with the document entity ID causes a residual policy to evaluate to true, is included in the set. What you would like to do is use these constraints to efficiently fetch the data that satisfies them. Since Cedar doesn’t have any way of knowing how your specific application stores data, it can’t do this on its own.
Fortunately, the Cedar language is pretty small, so it’s easy to convert it into another language that can be used to do that. Let’s imagine that for this sample application, our document metadata is stored in a relational database. We could translate our remaining Cedar residual into a SQL query we can submit to the database. If our metadata is in a table called documents, with the columns id, is_public, and owner , then we can translate our first residual into the following query:
SELECT id FROM documents WHERE
(true AND true AND owner == 'DocCloud::User::"Alice"')
||
(true AND is_public);
And our second residual would become:
SELECT id FROM documents WHERE (true AND is_public);
These queries could then be submitted to a database in order to retrieve the set of documents that Alice is authorized to access. Importantly, partial evaluation has already evaluated all of the authorization info that the database is unable to answer, such as whether or not the request was authenticated with MFA.
Caveats
One missing feature of partial evaluation is being able to make a guarantee to the partial evaluator that an unknown will be filled with a value of a certain type. This why the residuals above contain items like true && unknown(resource)["isPublic"] . The partial evaluator can’t guarantee that resource.isPublic is always a boolean, so it has to leave the && un-evaluated to preserve the error behavior if isPublic is a non-boolean. It would be ideal if true && unknown would partially evaluate to unknown. Expressions could be more aggressively constant-folded down to values if more type information was known. This remains an area for future work.