Why was Cedar created?
When Cedar launched in 2022, one of the common questions we received was "Why?". After all, there was no shortage of existing authorization grammars at the time. Creating another was not the initial intent. Yet, as we evaluated options, we struggled to find one that met our needs. This eventually informed the decision to create a new language and established its guiding principles.
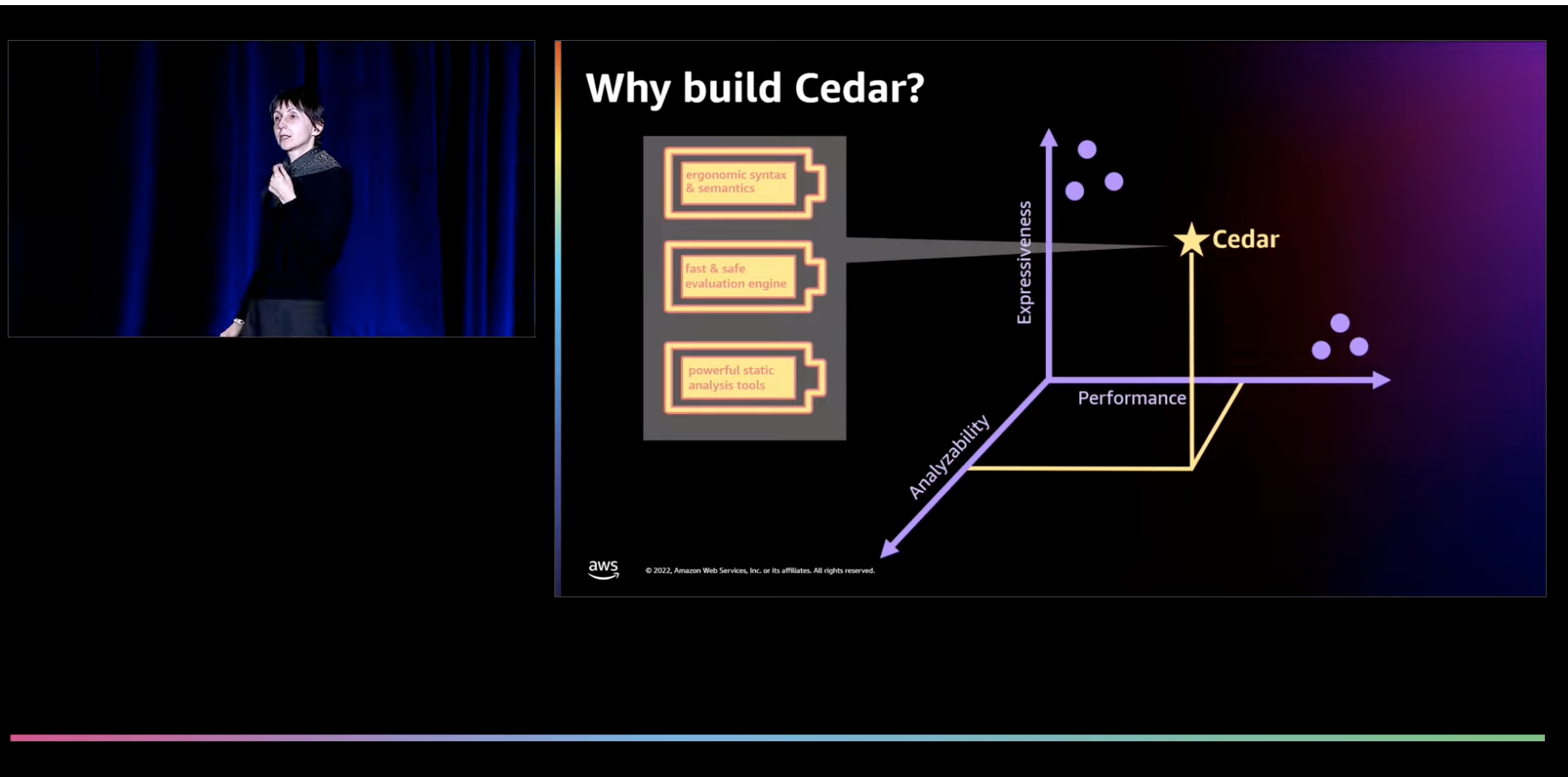
To frame the context, Cedar was originally developed in AWS to support services such as Amazon Verified Permissions and AWS Verified Access. Like most cloud offerings, our services typically share common characteristics which we wanted to hold true for authorization solutions, as well. Cloud services tend to be multi-tenant and seek to provide a high quality of service for all customers. If an individual authorization rule can take excessive time to run, or consume excessive system resources, this works against the quality of service goals for customers and was a behavior we sought to avoid in an authorization grammar. Cloud services also run at high scale and callers want them to behave flawlessly, making efficiency and correctness an important consideration. In terms of security, our authorization rules would be written by external customers and evaluated by the cloud service, making policies a form of untrusted code that needed to be evaluated safely. Lastly, we wanted the policy language to be understandable by a broad range of customers, and to allow for robust analysis of existing rules and the potential impacts of changing them.
All these criteria - performance, correctness, safety, analyzability – serviced as guideposts to the design of Cedar. While not all users will find themselves operating services at the same scale, we believe the criteria this demands are broadly beneficial in all domains.
In discrete terms, Cedar was designed to provide the following properties.
Bounded Latencies
Cedar is designed to make sub-millisecond authorization decisions for typical situations, regardless of the skill level of the policy author. No Cedar operators can result in blocking operations, non-terminating loops, or severe performance degradations.
No Sandboxing Required
In a high TPS system, the overhead of sandboxing every authorization decision would be impractical. Cedar policies are designed to be safely evaluated without security sandboxing, even if written by untrusted actors. Cedar contains no file system accessors, system calls, or networking operators.
Default-Deny and Order-Independent Evaluation
The Cedar evaluator will deny by default unless there exists at last one matching permit statement and no matching forbid statement. This evaluation criteria is designed to be simple, safe, and robust, and is not reliant on policy evaluation order.
Alternative authorization systems have sometimes offered more flexibility over the evaluation logic, including custom rules on policy precedence and override behavior. In recent years, there has been a general industry recognition that complexity in the human/technology interface is often a primary origin of security risk. In other words, people make mistakes, people get confused, and people click buttons to make something work without understanding why. Cedar adheres to a philosophy that a single safe-by-default evaluation mode is a preferred approach.
Ergonomic Syntax
Cedar is designed to be understandable by a broad audience. One of the design goals was that anyone should be able to read a Cedar policy and generally understand what it does without having any prior familiarity with the Cedar language.
In terms of writing policies, our design goal was that anyone with a technical skillset on par with writing SQL statements should be able to author Cedar policies. In addition, by including schema files, we wanted to make it possible to validate policies for correctness and to open the door to advanced editing capabilities such as autocompletion and more.
Support For Various Authorization Approaches
A number of well-known authorization patterns have developed over time, including RBAC, ABAC, and newer approaches such as ReBAC. All are useful in various circumstances and we didn't want to preclude customers from choosing an approach that worked best for them. Cedar is designed to support all well-known authorization patterns, and even allows them to be used in combination.
Verification-guided Development
In recognition of the important security role that Cedar plays, we wanted confidence that authorization decisions would be correct. To achieve this, we followed an approach we call verification-guided development. This approach uses automated reasoning and random differential testing to provide a high degree of trust in the implementation. My teammate Mike Hicks describes this approach in more detail in his blog post.
Amenable to Automated Analysis
Writing a policy is often the easiest part of an authorization solution. The more difficult part can be understanding what the current policies do, predicting the impact of a change, and proving to auditors that policies are correct.
Cedar was designed to support automated reasoning over a body of policies in order to enable provable assertions about system behavior.
Creating a language that is amenable to automated reasoning requires careful decision making about the supported data types and operators, as the technique relies on symbolic evaluation that considers every possible path through the code. The challenge is to keep paths sufficiently bounded so that reasoning over language statements remains tractable. For example, unbounded loops lead to an infinite, intractable number of possible paths. Even something as simple as choosing between sets vs. lists can have ramifications, as lists require the reasoning tools to consider the order that something appears and whether there can be more than one occurrence in the list, whereas sets do not. As a result, sets are more tractable for analysis. (Cedar only supports sets.)
Scalable to Large Numbers of Policies
When a system contains only a small number of authorization policies, deciding which policies to include in an authorization evaluation is a trivial matter; you can simply evaluate them all. However, as a system scales up to hundreds, thousands, or even millions of policies in a multi-tenant system, it is no longer practical to load all policies into memory to make an individual authorization decision. A more finely-tuned mechanism is required to determine which policy statements are relevant to a particular authorization query and which can be safely ignored. Cedar was designed to support this capability with a well-defined policy structure that includes a header designating the scope of the principals and resources to which a policy applies.
Striking the Right Balance
All these goals presented constraints that needed to be weighed against solving real-world authorization scenarios. After all, a robust authorization solution that can solve no real-world problems has a slim chance of adoption. Cedar's aim was to strike that balance, residing in a design space that is flexible enough for most scenarios, but structured enough to deliver the other goals.
For audiences interested in learning more, my teammate Emina Torlak presented this 23 minute session which dives deeper into the language design and syntactical choices of Cedar.
https://www.youtube.com/watch?v=k6pPcnLuOXY&t=1779s